COMPRESIÓN DE IMAXES
O principal inconveniente da fotografía dixital é,
sen dúbida, a cantidade de información que require e o tamaño
dos arquivos que xera. A capacidade de traballo e de almacenamento dos sistemas
informáticos vai en aumento, pero tamén nos imos afacendo a
dispor de máis megapíxeles. Isto fai que se manteña o
uso e o interese pola evolución das técnicas de compresión.
O tamaño dunha fotografía mentras se procesa
cun programa ou se visualiza nun explorador é o que corresponde ao
seu número de píxeles e profundidade de bits. A compresión,
en realidade, consiste en sustituir a cadea de datos por outra máis
curta cando se garda o arquivo.
Certos métodos son reversibles ("lossless"
en inglés), porque permiten a reconstrucción exacta do orixinal.
Pero con outros, a información orixinal só se recupera aproximadamente,
xa que se descarta unha parte dos datos ("lossy"), a cambio de relacións
de compresión moito maiores.
Compresión sen perdas
Distínguese entre sistemas adaptativos, non adaptativos e semiadaptativos,
segundo teñan en conta ou non as características do arquivo
a comprimir.
Os non adaptativos (código Huffman, CCITT) establecen a priori una
táboa de códigos coas combinacións de bits que máis
se repiten estatísticamente. A estas secuencias se asignan códigos
curtos, e a outras menos probables claves máis longas. O problema que
presentan é que un diccionario de claves único ten resultados
moi diferentes en distintos orixinais.
Un código tipo Huffman pode aplicarse de xeito semiadaptativo,
se se analisa primeiro a cadea de datos a comprimir e se crea unha táboa
a medida. Acádase maior compresión, pero introduce dous inconvenientes:
a perda de velocidade ao ter que ler o orixinal dúas veces, por unha
banda, e por outra a necesidade de incrustar no arquivo comprimido o índice
de claves.
Os compresores de uso xeral máis populares utilizan
métodos como éste, por iso tardan máis en empaquetar
os datos que en descomprimilos. O número de entradas da táboa
pode ser configurable.
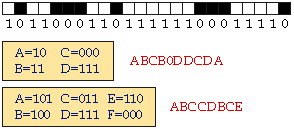
Exemplo de codificación dunha
liña de píxeles sobre unha táboa de 4 entradas e sobre
outra de 6 entradas
Entre os métodos adaptativos, o máis sinxelo
é o RLE (run lengh encode). Consiste en sustituir
series de valores repetidos por unha clave con indicador numérico.
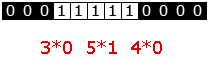
O
método RLE codifica series de píxeles repetidos
Esta secuencia de 12 valores anótase con 6 datos
Moitos outros métodos derivan deste, pero a súa
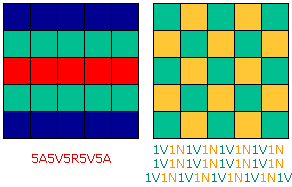
eficacia depende do tipo de imaxe. Os dous exemplos seguintes teñn
25 valores, pero mentras que o primeiro queda en 10 datos, o segundo (un caso
extremo) non reduce o seu tamaño, senón que o duplica. A anotación
de píxeles por series é adecuada en imaxes con zonas amplas
de cores uniformes, pero non noutras con cambios frecuentes de valor ou predominio
de texturas:
O sistema adaptativo LZ (de Abraham Lempel e Jacob Ziv), do
que deriva o LZW (Lempel-Ziv-Welch), é máis enxenioso e logra,
nunha lectura única, codificar repeticións sen crear unha táboa
de códigos. Cando se localiza una secuencia semellante a outra anterior,
sustituese por unha clave de dous valores, que din cántos pasos se
retrocede e cántos datos se repiten.
Rápido e fiable, emprégase en formatos universais como o GIF
ou o TIFF. Aínda que non acada relacións de compresión
moi altas, normalmente aforra un tercio do arquivo.
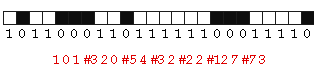
Comportamento
do algoritmo LZ
# 3 2 significa retroceder 3 píxeles e repetir 2
# 12 7 significa retroceder 12 píxeles e repetir 7
Compresión con perdas
Dentro desta categoría é universalmente coñecido pola
súa eficacia o formato JPEG, aínda que cabe mencionar tamén
o método Fractal, que analisa a imaxe dividíndoa en bloques
e definindo rexións a maior escala. Rastréxanse estas rexións
de xeito que mediante escalado, rotación, reflexo ou combinación
de transformacións poidan corresponder a un bloque. Anótanse
correspondencias e testéanse, seleccionando as que permitan unha reconstrucción
máis semellante dos datos.
A compresión baseada na xeometría fractal acada
moi boas relacións de compresión e, en certo modo, vectoriza
as características da imaxe, de xeito que se pode reconstruir ésta
a diferente escala. O principal inconveniente é a lentitude do proceso,
debido á grande cantidade de recursos que esixen os cálculos.
O sistema proposto polo JPEG (Grupo de Expertos en Fotografía Reunidos)
é unha combinación de varias técnicas que crea un arquivo
JPG cun nivel de compresión regulable capaz de reducir nalgúns
casos o peso informático da imaxe a menos do 1%. O proceso estándar
consta de cinco pasos:
1. Converter a imaxe a un modo de cor que defina a luminancia
nunha canle, como YCC ou LAB. Os bitmaps pásanse a grises, mentras
que nas escalas de grises se obvia este paso.
2. Dado que ópticamente somos capaces de ver un cambio
sutil na luminosidade moito antes que na tonalidade cromática, iguálase
o ton en cada grupo de catro píxeles, respeitando os valores individuais
de luz.
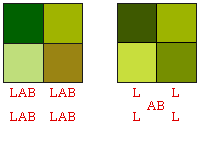
En
modo LAB, cada píxel ten un valor L de luz
e dous valores AB para definir a cor
Obsérvese como só este paso da compresión jpg supón
unha diminución do 50% dos datos a anotar
3. A imaxe divídese en bloques de 8 x 8 píxeles.
Para cada subimaxe anótase o valor promedio, a amplitude da oscilación
de valores e unha descrición frecuencial desta oscilación mediante
unha función de tipo Fourier, chamada Transformada Discreta do Coseno
(TDC), na que se combinan varios parámetros de onda. Cantos máis
parámetros, mellor correspondencia haberá entre a función
e a secuencia de valores; con poucos datos, conservaremos os básicos.
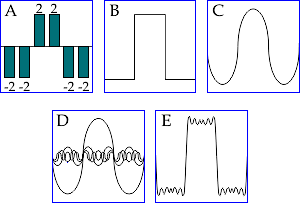
A
oscilación sobre un valor medio (A) pode representarse por unha forma
liñal (B),
e ésta pode
reproducirse como unha suma de ondas.
A onda C descrebe a forma B moito peor que as 5 ondas do gráfico D
que vemos sumadas en E
4. Os valores TDC cuantifícanse á baixa, dividíndoos
por un factor enteiro. O número de coeficientes de onda e o factor
a dividir determinan a profundidade da compresión, que é o que
decidimos nunha escala que, segundo o programa, vai de 1 a 10, de 1 a 12 ou
de 0 a 100, pero sempre xogando inversamente entre o nivel de compresión
e a calidade do resultado. Tras esta cuantificación, abundan as fraccións
decimais, que se redondean ao enteiro máis próximo. Deste xeito,
resulta unha cadea de datos con moitas probabilidades de reiteración.
5. Ao resultado aplícaselle a codificación estadística
de Huffman, compactando as cadeas máis repetidas en códigos
breves.
A compresión con perda deixa rastro
Os efectos negativos dunha excesiva compresión poden ser un empobrecemento
do ton e a nitidez global, que notaríamos máis ben nunha impresión,
e a aparición de artefactos a nivel local visibles sobre todo en pantalla,
aínda que JPG sexa un formato habitual en Internet. Estas pegadas son
menores en imaxes grandes, de varios megapíxeles, nas que as baldosas
de 8 x 8 píxeles son menos importantes para o detalle e a codificación
da derradeira fase é moito máis efectiva. Acádanse así
boas relacións de compresión, aínda que indiquemos niveis
de calidade media-alta.
Os efectos máis típicos son a aparición
dos bloques de 8 x 8 píxeles, o ruido cromático nas zonas escuras
e a alteración das siluetas, que se ven borrosas en imaxes de pouca
resolución e reverberadas nas máis grandes.
A 
B 
C 
A=
imaxe orixinal. B= reberveracións nos bordos por unha excesiva compresión.
C= detalle dos bloques de 8x8 píxeles
A reverberación é producida polas baldosas que
coinciden cun bordo marcado. A súa reconstrucción é moito
más irregular que as das súas veciñas, que coinciden
nunha zona de menor oscilación e resultan moito máis homoxéneas.
Así, prodúcense pinceladas de falso contraste a varios píxeles
de distancia da verdadeira silueta.
A solución pasa por acadar unha mellor correspondencia
formal (que hoxe se busca nas formas Wavelet, un tipo de patróns de
onda deseñables que poden ser sinusoidais ou non) e establecerse cunha
duración finita. Combinando Wavelets (TDW), poden describirse formas
complexas con moitos menos coeficientes. Tal é a base de novas técnicas,
como EZW, SPIHT, MrSID ou JPEG 2000, que queren ser a alternativa ao actual
JPG.
|
